Edge Computing
2025-09-04
(Material for this lecture heavily derived from the work of Grace Lewis, especially the paper listed in references.)
Edge Computing is a paradigm that explores moving processing and storage capacity to the ‘edge’ of the network. Where Cloud moves processing directly to a remote datacenter (usually run by some other company), Edge (and the intermediary, “Fog”), either leave processing or storage on-node (e.g., within a smart home hub, or a car) or send it to a closer/cheaper/more accessible intermediary.
Consider the case of a drone being used for crop surveillance (or a satellite). The drone is imaging terabytes of data per day, but most of the data is probably not important (see Performance tactics). We might only want to see places where chlorophyll (plant productivity) is below a given threshold.
We therefore have a few design choices. One, we put a big storage device on the drone, let it process the data on-device (“edge”), and send the processed data to our cloud endpoint (some analytics dashboard, for example, using Kibana). Two, we could send all the raw data to the endpoint, and let the endpoint handle data storage. What’s the tradeoff here?
(Processing vs storage capacity vs network bandwidth)
How would your decision change if the drone was flying on Mars, instead of Earth?
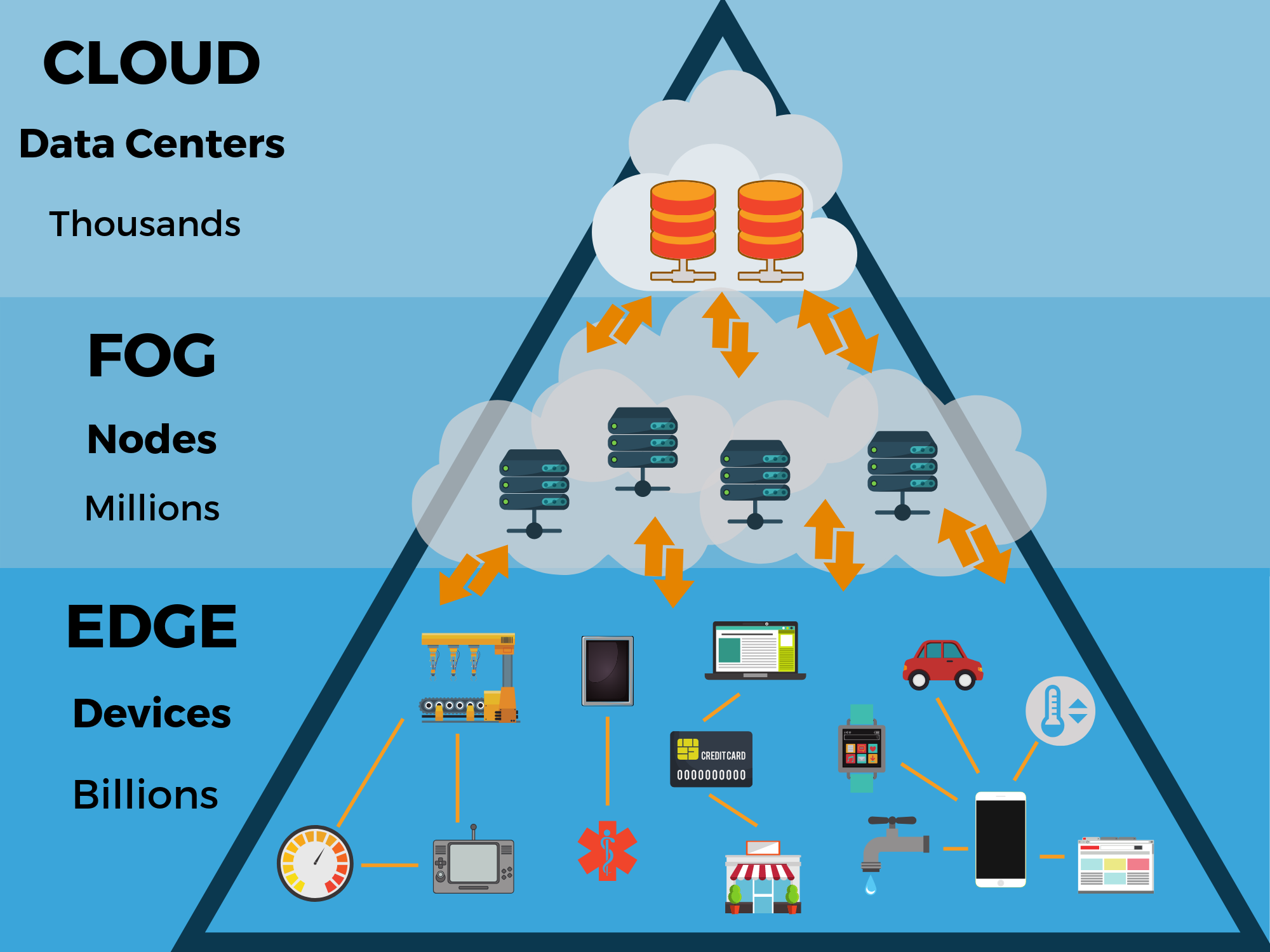
edge-graphic comparing it to cloud
Within the concept of edge, cyber-foraging is a technique to enable mobile devices to extend their computing power and storage by offloading computation or data to more powerful servers located in the cloud or in single-hop proximity. One obvious application area is (?) - augmented reality computing. Cloudlets are essentially small, flexible data centres that can be quickly provisioned
Benefits: * energy efficiency, * reduced latency, and * increased availability,
Tactics
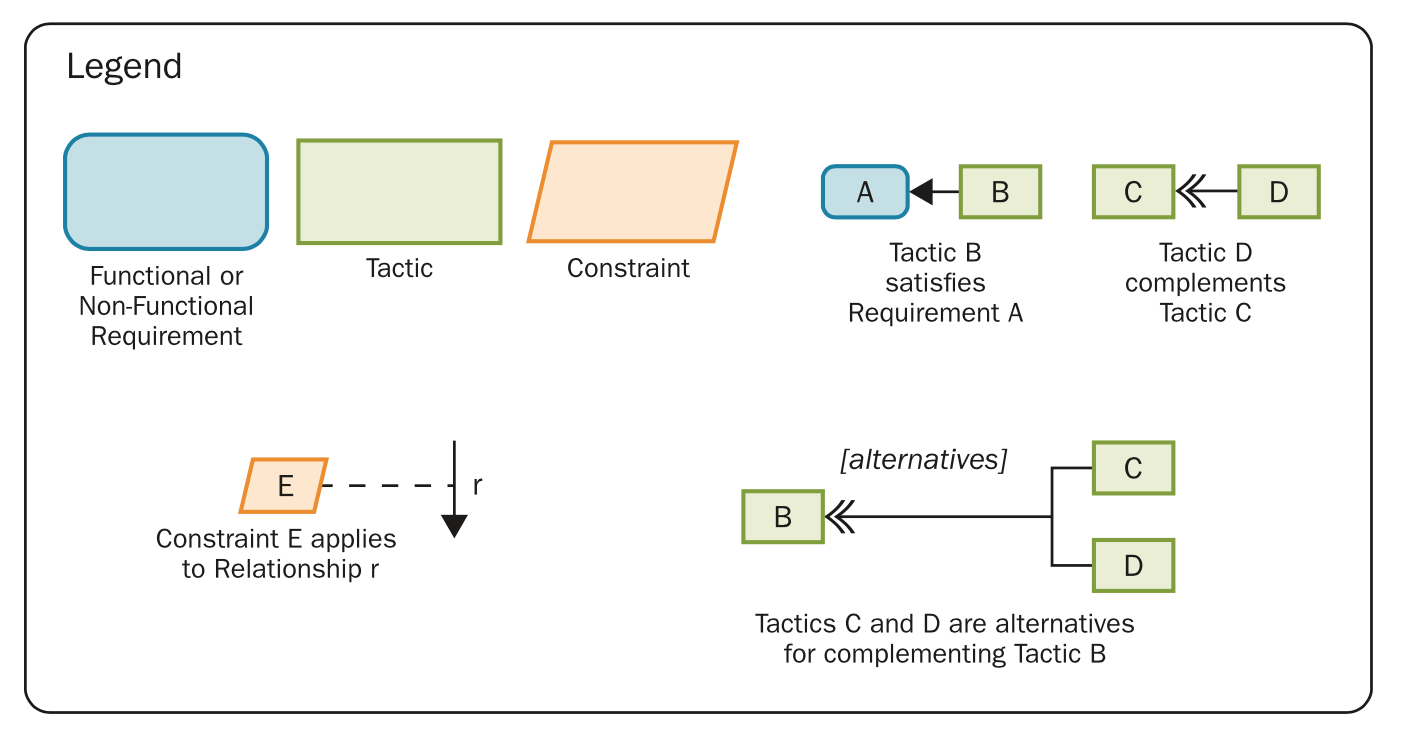
tactic legend
Computation staging
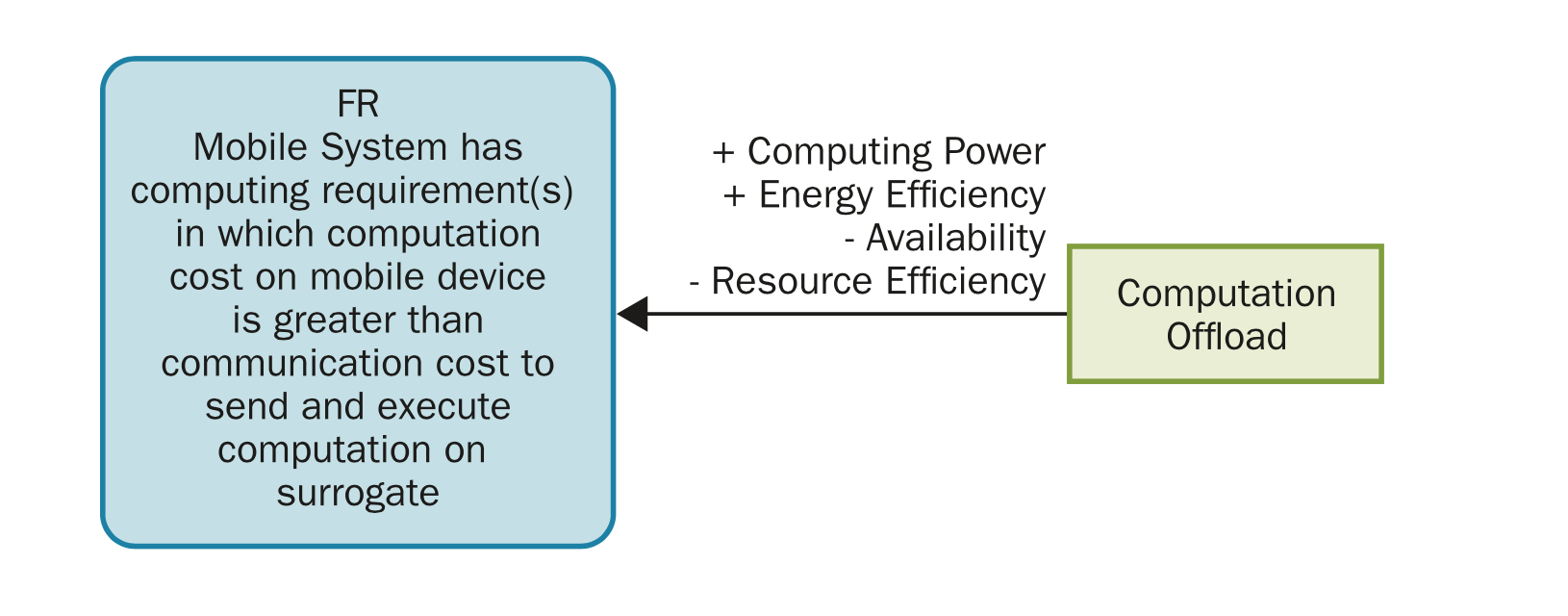
Data Staging
AgroTempus Case Study
One need in countries with weaker national connectivity is to support data intensive, computational processing tasks without connecting to (or assuming a connection to) a high capacity data centre such as AWS Us-East. Often these countries have decent cell networks but poor computer/data networks. Thus surrogates for data collection are usually cell phones or Raspberry PIs, with limited on-device processing and storage. An Edge computing approach could periodically retrieve data from the surrogates and then upload it to a data centre (possibly by driving it in via “SneakerNet”).
AgroTempus is a case study that looks at support for doing this.
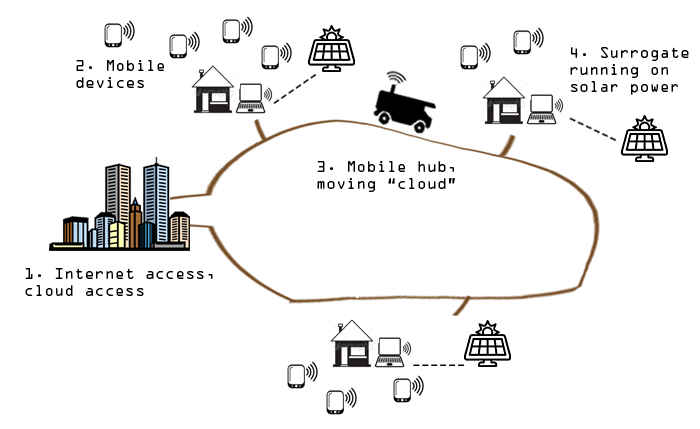
As a research project, the authors looked at how the system could be implemented using the cyber-foraging tactics below. Like the SKA project, AgroTempus ran experiments to see if the tactics made sense for the system. E.g., to test data offload, the code implements weather forecasting by offloading data to the mobile hub, then performing the calculation, then sending the simple prediction back to the mobile device.
GigaSight

Requirements from previously:
- High bandwidth
- Connection Quality
- Video quality
- Opt-in / PII
- Spatial coverage
- Accuracy
- Formats/files
- Devices
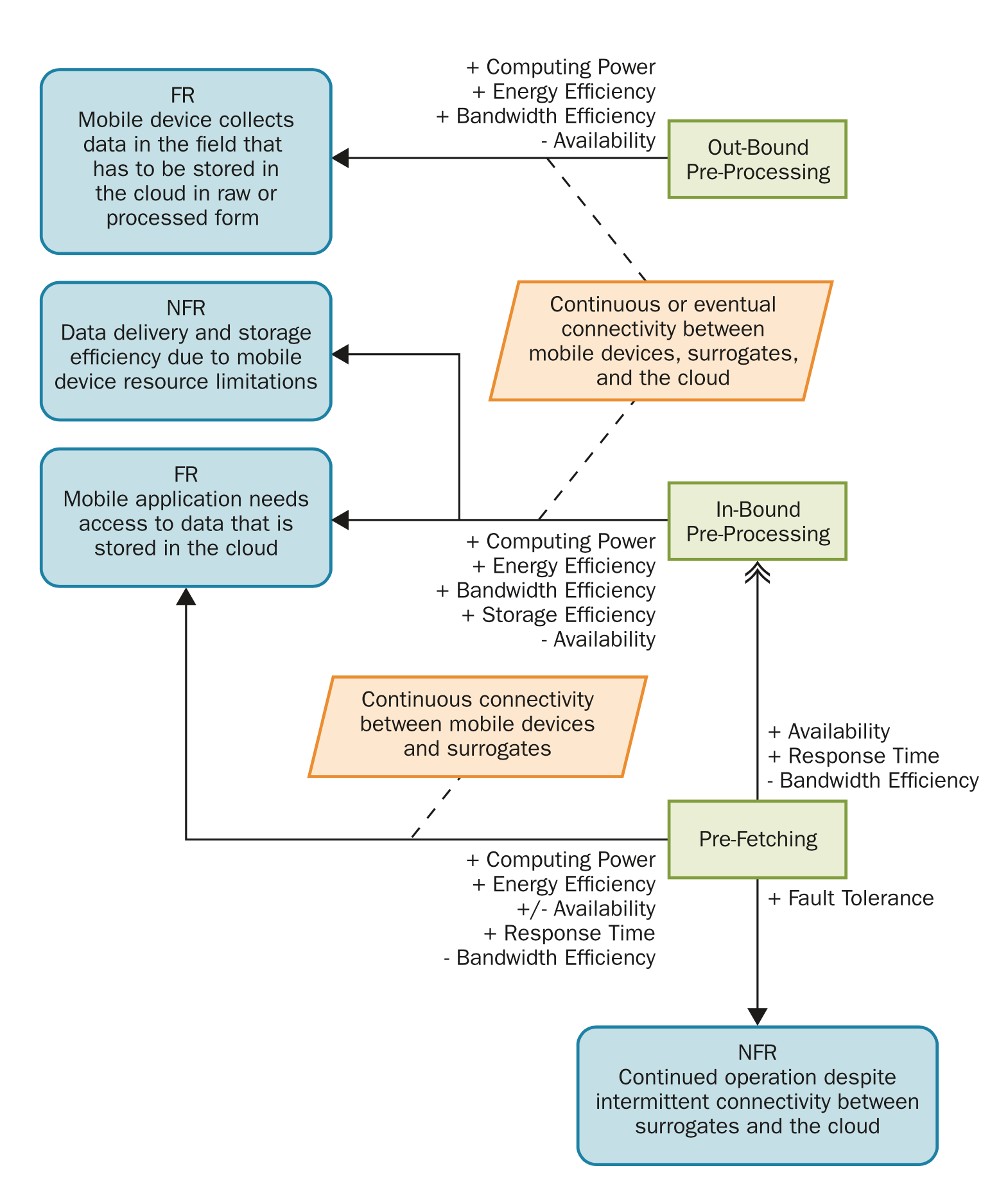
GigaSight is a cyber-foraging system targeted at continuous collection of crowd-sourced video from mobile devices and wearables [7]. Given the potentially-sensitive nature of video, GigaSight collects video on surrogates called cloudlets where privacy-sensitive information is automatically removed from the video based on user-defined privacy settings related to time, location, and content — a process called denaturing. Denatured video is then indexed and resulting tags and metadata are uploaded to a cloud catalog where users can perform content-based searches on the total catalog of denatured videos.
The key QAS to consider in your design is
“In order to support adherence to GDPR requirements and network saturation risk, when a user video is sent to Gigasight, Gigasight’s cloudlet processes the video and denatures the possible PII - blurring faces - off-device, before sending it to the final cloud-based storage bucket”.
Using the tactics tree below, pick 3+ tactics to use in implementing the Gigasight system.
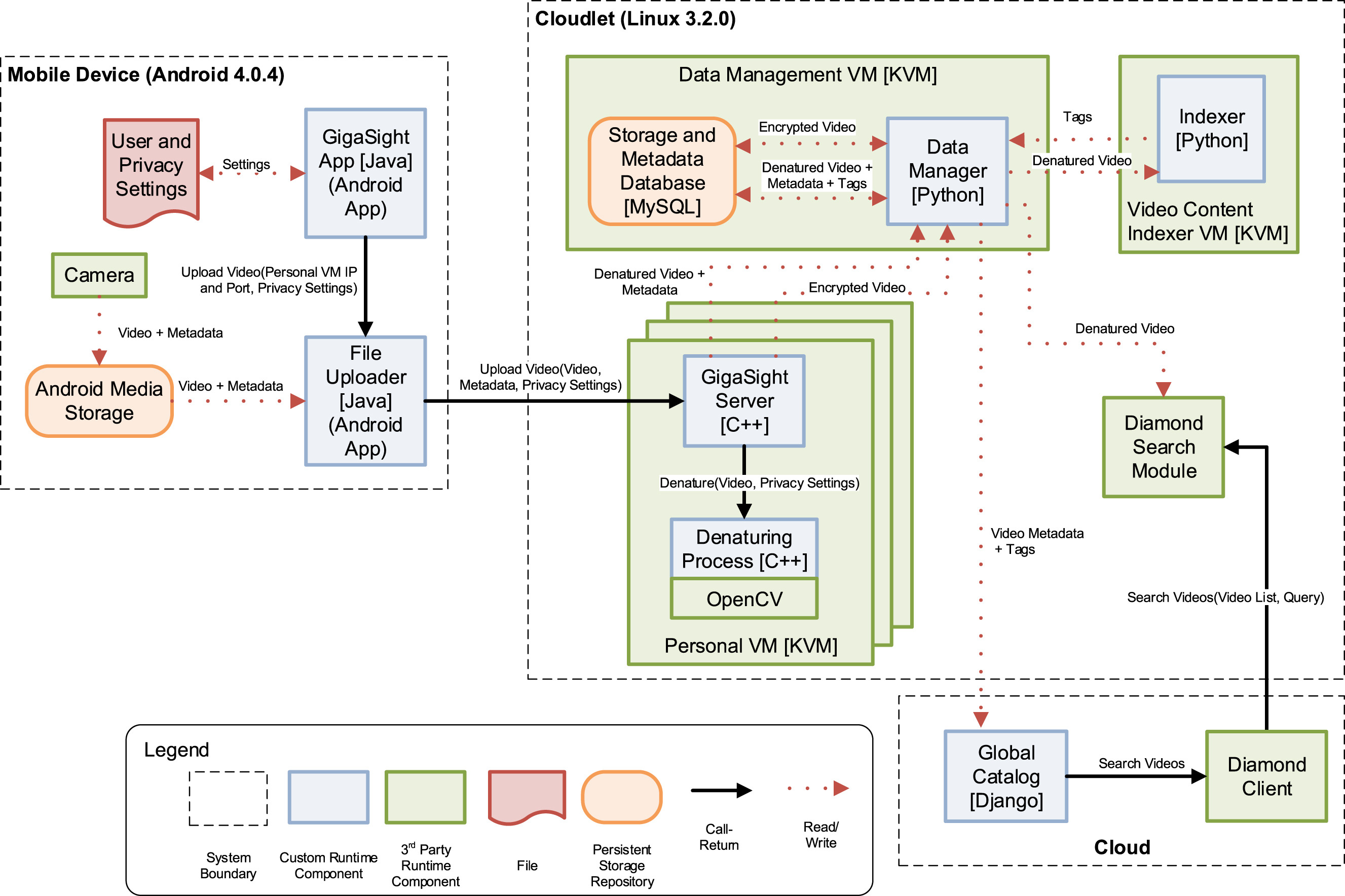
Here’s an application of “outbound preprocessing” to the Gigasight design: 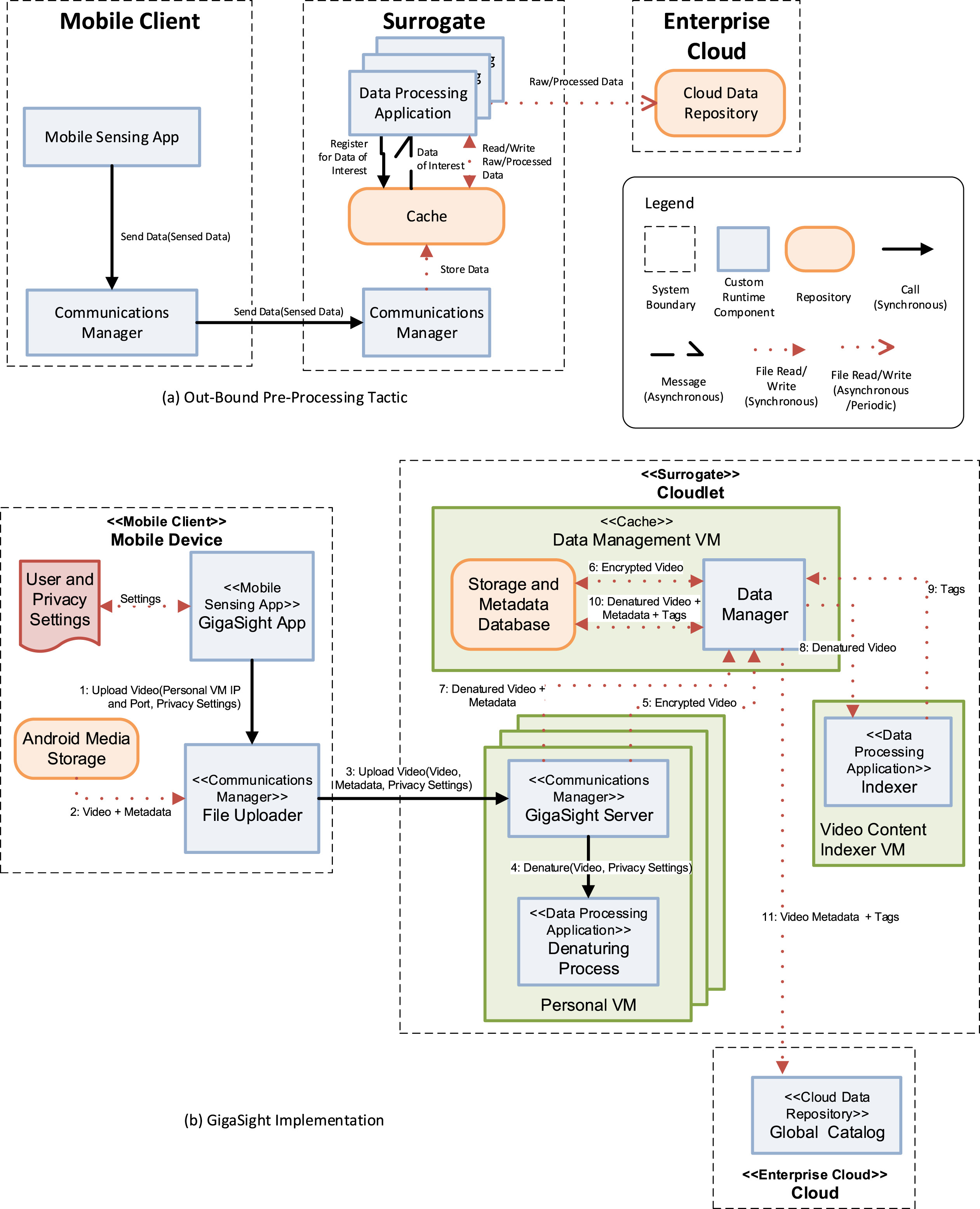
Tactics Tree
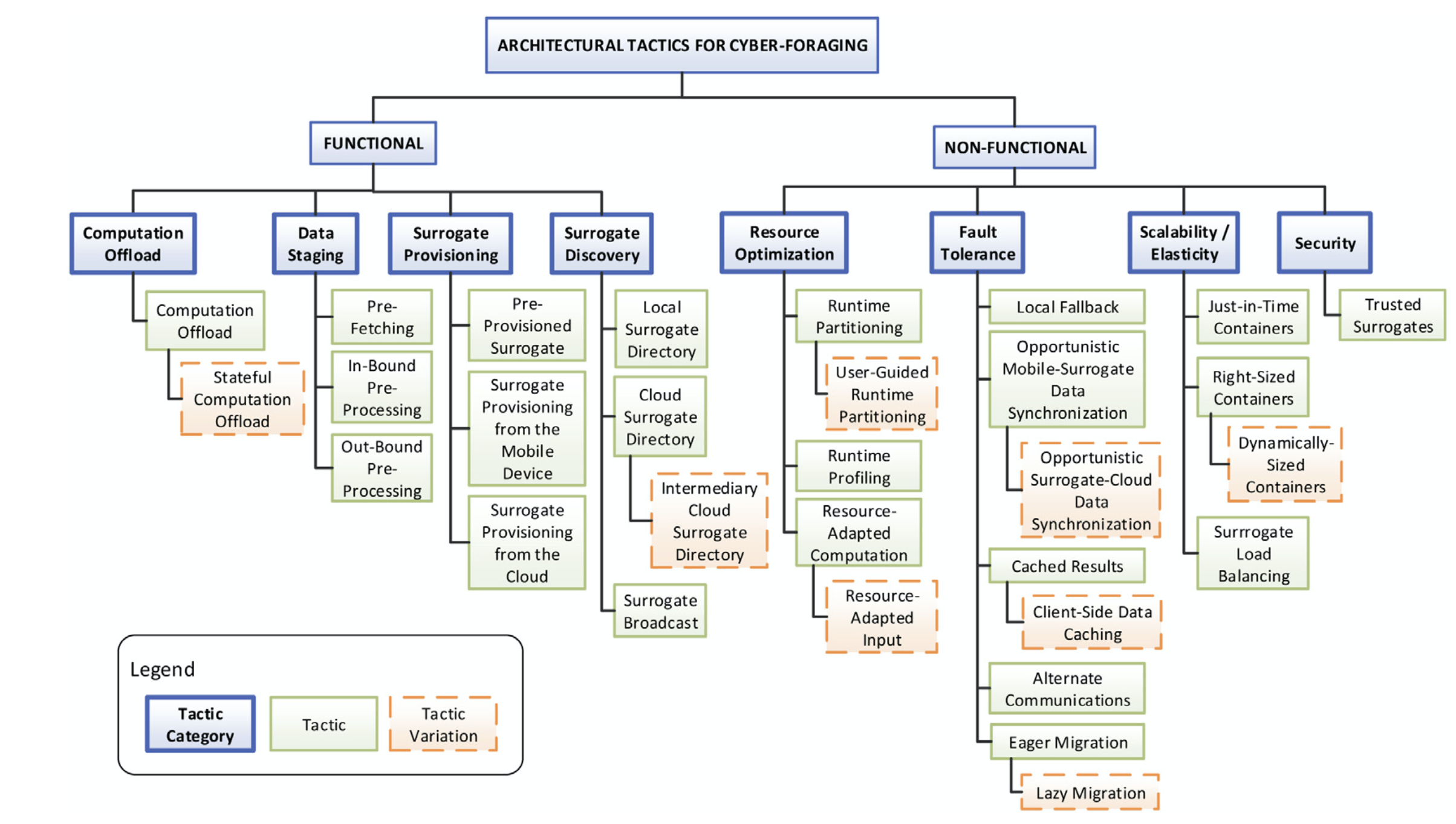
tactics for cyber-foraging, completed
